从实时语音到家庭机器人交互闭环
01 · 项目背景
自然语音正在成为家庭机器人的核心入口
传统“唤醒词 + 命令词”只能覆盖少量固定任务,而家庭陪伴、老人看护、儿童教育需要更自然、更连续、更个性化的对话体验。
- 低延迟:用户开口到 AI 开始回复需要接近实时。
- 可打断:用户在 AI 说话时可以插话,系统必须立即响应。
- 无回声:音箱输出不能被麦克风重新录入造成自激循环。
- 个性化:儿童、老人、成年人需要不同语气、话题和背景知识。

PiCarVoice 以自然语音作为家庭机器人交互入口
02 · 项目目标
端到端可落地的家庭机器人语音系统
- 双平台一致:桌面开发端与 Pi5 部署端保持一致体验。
- 接入实时大模型:使用端到端 Audio-to-Audio 多模态语音能力。
- 图形化前端:唤醒、音量、挂断、状态指示直观可见。
- 可打断 + 抗回声:接近商用品质的自然对话体验。
- 人设与背景注入:通过 system prompt 实现角色个性化。
- 小车集成:扩展为语音驱动的家庭机器人。
<1s目标级低延迟体验
AEC回声路径切断
Barge-in真实插话打断
桌面端与 Pi5 端共享同一套前端交互设计
06 · VAD 双重门控
静默时不上传,无效声音不过网
Pi5 端采用能量阈值 + VAD 的双重门控,在静默时段完全不上传音频,减少网络流量、模型 token 消耗和误触发。
麦克风音频帧
│
├─ 能量低于阈值 → 本地过滤
│
└─ 能量超过阈值
│
├─ VAD 判断非语音 → 丢弃
│
└─ VAD 判断为语音 → 上传实时语音模型Energy低成本快速粗筛
VAD语音活动二次判定
Upload只上传有效语音
本地门控降低模型调用压力,让待命首屏更像家庭设备而不是开发 Demo
09 · Flutter 前端
桌面 + 嵌入式共享同一套交互
- 橙色电源按钮:后端未启动时点击唤起服务。
- 蓝色麦克风按钮:已连接后点击开始对话。
- 红色挂断按钮:对话中点击立即结束。
- 音量滑块:始终悬浮于下方,便于家庭场景快速调节。
- 状态指示:让离线、待命、对话中三个状态清晰可见。
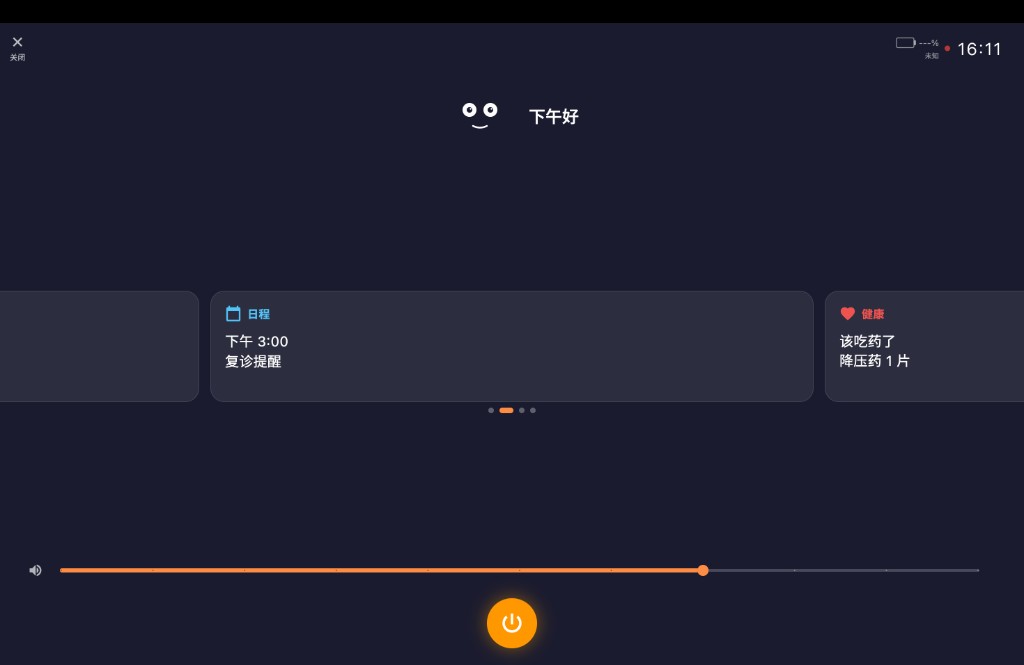
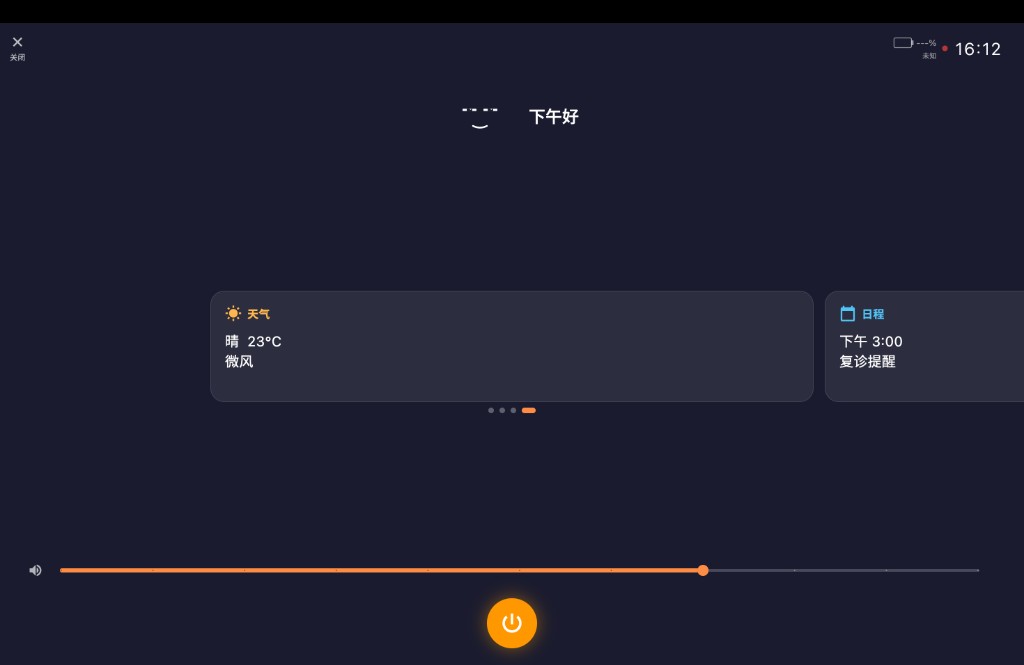
待命首屏:日程、天气、健康提醒与底部语音入口
11 · 应用场景
儿童陪伴、老人看护与教学演示
- 儿童 AI 陪伴机器人:陪学英语、讲故事、解释机械电子知识。
- 独居老人家庭护理助手:注入家庭信息、健康档案与用药计划,主动提醒与应急响应。
- 家庭服务小车:结合底盘,实现室内语音导航与环境感知问答。
- 教育科研演示平台:用于 AI、机器人、物联网课程的参考实现。
陪伴角色化自然对话
看护日程健康提醒
服务语音驱动小车
项目以家庭机器人真实交互体验为目标,而不是单次语音问答 Demo